![]() Go to frame view (Recommended only for
screen resolution 1024x768)
Go to frame view (Recommended only for
screen resolution 1024x768)
8 Macromolecular Structure of DNA and RNA
A large body of literature is concerned with the structure of DNA and RNA. Some of the books and reviews dealing with the subject are listed at the end of this chapter. Here, we shall give a brief outline of the current concepts regarding the principles of spatial organization of DNA and RNA macromolecules and those of their features that offer an insight into their chemical properties and interactions with various ligands.
8.1 DNA
8.1.1 The Watson and Crick Model
In the spring of 1953, J. Watson and E Crick published a short paper with a description of a new model of DNA structure. This report on one of the most important discoveries of our times had turned out to be seminal in many fields of natural sciences.
Proceeding from the available data on the structure of heterocyclic bases, conformation of nucleosides, the internucleotide linkage in DNAs and their nucleotide composition (Chargaffs rules), Watson and Crick decoded the X-ray fiber diffraction patterns representing the paracrystalline form of DNA emerging at a relative humidity in excess of 80 per cent and a high concentration of counter-ions (Li+) in the sample. According to their hypothesis, the DNA molecule is represented by a symmetrical helix formed by two polydeoxyribonucleotide chains twisted one with respect to the other around a common axis (Fig. 8-1). The diameter of the helix is virtually constant over the entire length and equals 1.8 nm (18 Å). The pitch per helix turn, which corresponds to its identity period, is 3.37 nm (33.7 Å). There are ten bases per pitch in one strand. The base planes are thus spaced about 0.34 nm (3.4 Å) apart. They are perpendicular to the axis of the helix. The planes of the carbohydrate moieties are almost parallel to helix axis.
As can be seen from Figure 8-1, the sugar-phosphate backbone of the molecule points toward the outside of the helix, and two grooves differing in size can be discerned on its surface, the major groove being about 2.2 nm (22 A) wide and the minor one, about 1.2 nm (12 A) wide. The helix is right-handed. Its polydeoxyribonucleotide chains are antiparallel: this means that if we move along the axis of the helix from one end to the other, the phosphodiester bonds in one chain will be passed in the 3'
® 5' direction and in the other, in the 5' ® 3' direction. In other words, the linear DNA molecule terminates, in each direction, in the 5' end of one chain and the 3' end of the other.The symmetry of the helix implies that for each purine base in one chain there is a matching pyrimidine base in the other chain. As has already been
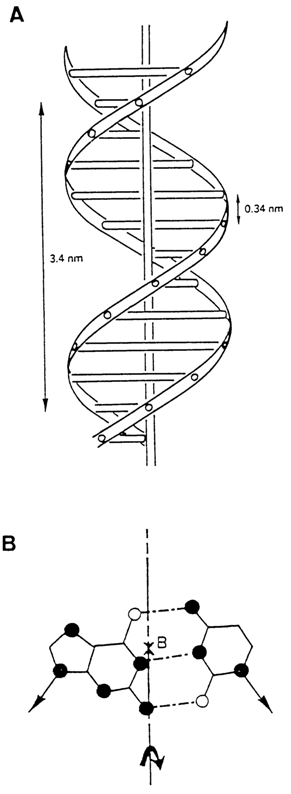
Fig. 8-1. (A) Watson and Crick model of B form of DNA and (B) location of helix axis (x) relative to a base-pair.
emphasized, this requirement is met by formation of complementary base pairs - that is, adenines and guanines of one chain are paired with thymines and cytosines of the other respectively (and vice versa).
Thus, the nucleotide sequence in one chain of the DNA molecule predetermines that in the other chain.
This principle is an important corollary of the Watson and Crick model as it provides a lucid explanation in chemical terms of the fundamental biological role of DNA - storage and faultless transmission of genetic information.
The only other thing to be added in conclusion of this brief description of the Watson and Crick model is the fact that the angle between the neighboring base pairs (the angle between the straight lines connecting the C1' atoms in the adjacent complementary pairs) is 360. In subsequent writings, the double helix of DNA, whose model was proposed by Watson and Crick started being referred to as the B form of DNA or B-DNA. DNA exists predominantly in this form in the cell.
8.1.2 Polymorphism of the Double Helix of DNA
Although the structure of DNA helices is extremely rigid, it can be changed under certain conditions. At a relative humidity below 80 per cent or at a low concentration of counter-ions in the sample, DNA exists in a crystalline form also known as the A form. The latter is also a right-handed double helix with antiparallel chains. However, it differs markedly from the B form in many ways. If the helix axis in the B form passes through the center of complementary pairs, base pairs in the A form are nearly 0.5 nm (5 Å) off the axis and lie along the periphery of the macromolecule (which is clearly seen on the cross-sectional views of the helix in Fig. 8-2) with the result that DNA in the A form has the configuration of a spiral stair. Moreover, base pairs are not normal to the axis of the helix (the angle with the perpendicular is about 200), and the bases themselves are not coplanar within a pair. The helix rise per base pair in A-DNA is much smaller and equals 0.23 to 0.26 nm (2.3-2.6 Å).
Such a significant difference between the A and B forms of DNA helices becomes better understood after analysis of the conformation of deoxyribose in the mononucleotide residues forming these helices. It has been found that the sugar in the A form of DNA has a C3'-endo-conformation, whereas in the B form it has a C2'-endo- (or the closely similar C3'-exo-) conformation. It is due to this difference in deoxyribose puckering that we have the two forms of DNA helices considered here. One should also remember that the distance between phosphates in nucleoside diphosphate depends largely on the sugar conformation (see Fig. 7-9). For the B and A forms, the difference in the distance between two adjacent phosphorus atoms on the DNA chain is about 0.11 nm. This difference greatly affects the shape of the helix.
The C2'-endo-conformation of deoxyribose has also been revealed in forms C (lithium salt of DNA at a humidity below 66 %) and T (glucosylated DNA of bacteriophages) of DNA. At the same time, as will be shown below, ribose in double-stranded RNAs strongly reminiscent of A-DNA has a C3'-endo-conformation. This gives every reason to assume two families of helical nucleic acids - a family of A forms and that of B forms.
By virtue of the A and B forms of double-stranded DNAs having characteristic and widely different CD spectra, their interconversions can be observed in solution as well (Fig. 8-3A). Studies based on this approach have shown that the B-A transition (which occurs as the alcohol concentration in the solution increases) is essentially cooperative. At the same time, the change in the form of DNA helices within a family (i. e., without alteration of the sugar conformation) proceeds smoothly.
The capacity of the double helix of DNA for conformational changes becomes more manifest when it passes from the right- to left-handed form.
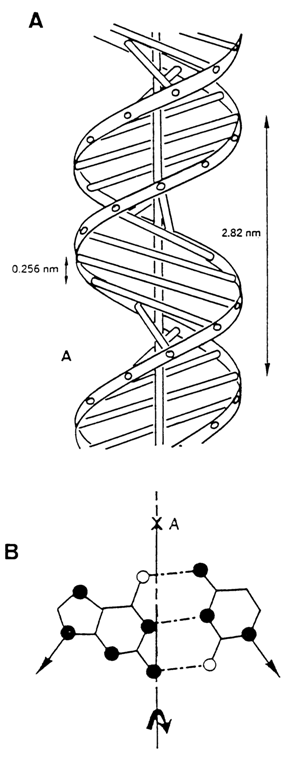
Fig. 8-2. (A) Model of DNA structure in A form and (B) location of helix axis (x) relative to a base-pair.
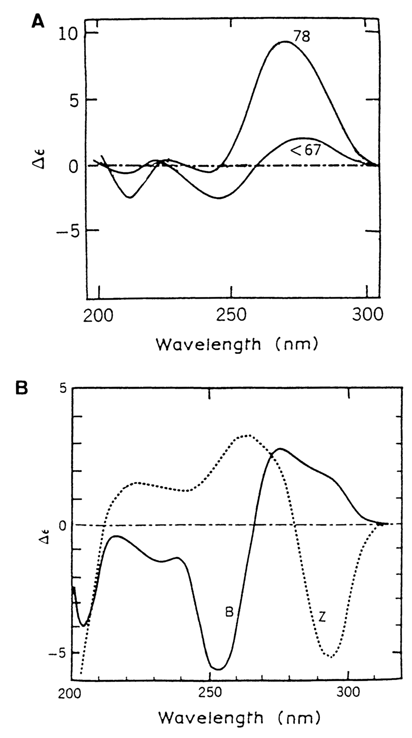
Fig. 8-3. CD spectra of DNA (A) - A and B forms; (B) - B and Z forms. Numbers at the curves indicate percentage of ethanol (adapted from W Guschlbauer, Polynucleotides,in Encyclopedia of Polymer Science and Engineering 12, 699-785 (1988)).
The earliest hypothesis of left-handed double helices was prompted by analyses of the CD spectra of a polynucleotide with an alternating d(GC)n sequence. Poly-d(GC) chains are self-complementary and form, in a solution of low ionic strength, duplexes producing the usual CD spectra typical of the B form. However, as the ionic strength goes up, their CD spectrum undergoes inversion (Fig. 8-3B). This may be indicative of the helix changing its handedness.
Indeed, when oligo- and polynucleotides with alternating G and C sequences were crystallized from solutions with high salt concentrations, X-ray structural analysis confirmed the existence of a left-handed helix which became known as Z-DNA (Fig. 8-4). It has a remarkable feature, namely, alternation of nucleotide conformations: if the sugar moieties in the dC units have a C2' endo-conformation and the base, an anti-conformation, in the dG units deoxyriboses are in a C3'-endo-conformation and the base, in a syn-conformation.
Thus, the repeating unit in the Z form of DNA consists of two base pairs, and not one as in the B and A forms; as a result, the line connecting the phosphate groups takes a sharp turn and assumes a zigzag shape (hence the name Z form). As compared to the B form, the left-handed Z form is marked by a different pattern of base stacking: strong and weak interplanar interactions also alternate.
Analysis of the Z-DNA model illustrated in Figure 8-4 makes it easy to understand why the B
® Z transition occurs only in solutions of extremely high ionic strength: in contrast to B-DNA, the distance between phosphate groups in the Z form across the groove is small - only 0.77 nm (7.7 Å) (in B-DNA it is 1.17 nm or 11.7 Å), and a left-handed helix may exist only provided the charges at the phosphates are screened.The Z form of DNA is also stabilized by some chemical modifications of heterocyclic bases, such as bromination of deoxyguanosine at C8 or methylation of deoxycytidine at C5. In the former case, incorporation of a bulky substituent stabilizes the syn-conformation of G, typical of Z-DNA. In the latter case (which, incidentally, is nothing but a natural modification of C, regulating gene activity), the methyl groups come closer together in the groove of the left-handed helix and enter into hydrophobic interactions, thereby changing the hydration of the DNA helix. In both cases, the left-handed helix is stable at a moderate ionic strength, too.
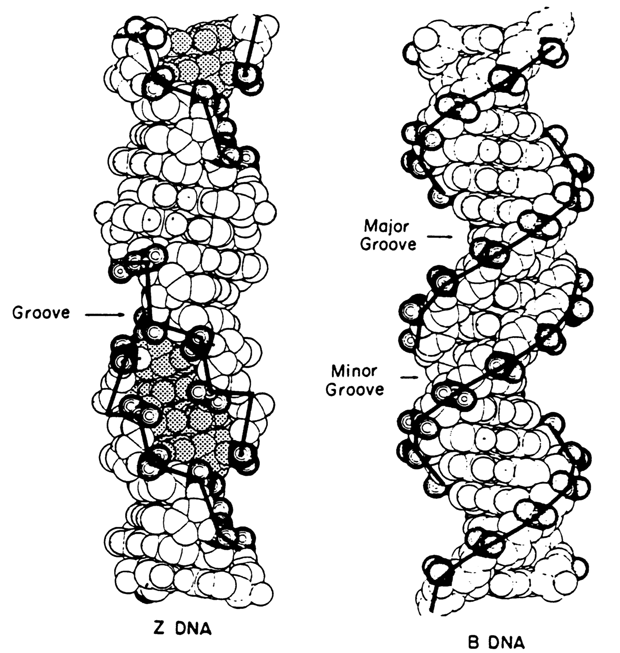
Fig. 8-4. Model of DNA structure in Z form. B form DNA is shown for comparison (adapted from A. Rich et al., J. Biomol. Structures and Dynamics, 1, 1-20 (1983)).
The Z form is typical not only of dCdG units but also many other alternating sequences, for example, polyd(AC) and polyd(GT) units. Interestingly, a B-DNA helix may feature local segments in A or Z conformation. This has given rise to many hypotheses as regards the functional role of such segments. None the less, the question as to DNA having such conformations in vivo remains open.
8.1.3 Single-Crystal X-Ray Structures of DNA
For quite some time, X-ray diffraction analysis on fibres has been the primary method for studying helices formed by DNA and other complementary polynucleotides. Its resolution is not very high, which is why doubts arose from time to time about the Watson and Crick model. In the early eighties, single crystals of synthetic oligodeoxyribonucleotide duplexes were produced.
Investigation of single crystals by X-ray structural analysis with atomic resolution not only confirmed the basic characteristics of A- and B-DNA revealed by X-ray diffraction studies on fibres (Fig. 8-5 and Table 8-1), but also led to a discovery of a rather important and quite unexpected feature of the B form of DNA.
Unlike A- and Z-DNA, whose helices have parameters independent of the nucleotide composition and, therefore, are structurally homogeneous, in B-DNA marked differences between individual base pairs are observed. These differences manifest themselves primarily in the mutual arrangement of bases within a complementary pair and the mutual orientation of adjacent pairs. As a result, each particular dinucleotide sequence has its characteristic parameters in the B-helix.
For example, in the self-complementary dodecamer d(CGCGAATTCGCG) the mean turn angle between bases is 35.90 (Table 8-1). At the same time, differences in this parameter for individual base pairs range from 27.40 to 41.90, which corresponds from 13.1 to 8.6 base pairs per turn of the helix. Single-crystal X-ray studies have also shown that base pairs in this duplex differ widely in the propeller twist or, in other words, the angle between the base planes within a complementary pair, arising as a consequence of departure of the bases from coplanarity within the pair. Such conformational mobility of the B form of DNA allows the neighboring bases of its chains to overlap more effectively.
There is no doubt that the sequence-specific microheterogeneity of DNA is extremely important for functional interactions with various ligands.
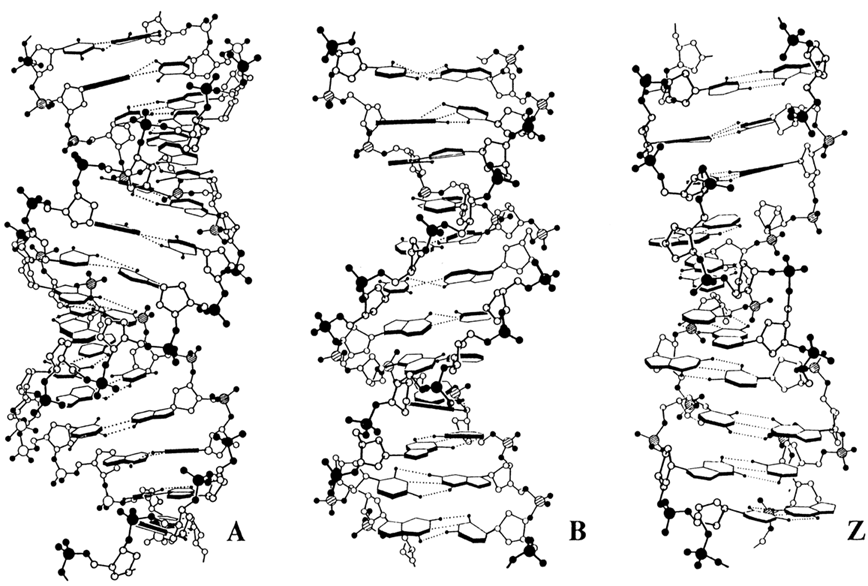
Fig.8-5. Molecular models of B, A and Z forms of DNA from single-crystal studies
Table 8-1. Structural Parameters of DNAs from Single-Crystal X-ray Structures*.

*Data from R. E. Dickerson and H. R. Drew, J. Mol. Biol., 152, 723-736 (1981). R. E. Dickerson, J. Mol. Biol., 166, 419-441 (1983).
8.1.4 Denaturation and Renaturation of DNA
Since deoxyribonucleic acids belong to the category of double-stranded polynucleotides with complementary sequences, the stability of their molecules is determined by the same factors and the denaturation process is given by the same parameters as in the simple duplexes considered above.
However, as opposed to most synthetic double-stranded complexes made up of homopolynucleotides or polynucleotides with regularly alternating nucleotide sequences, DNA molecules are extremely heterogeneous in nucleotide composition. In other words, any natural DNA has segments more abundant either in G . C or A . T pairs. Therefore, the "helix
® coil" transition in DNA is in marked contrast with processes of the "all" or "none" type (true phase transitions). It is believed that defects arise in the double helix in the course of denaturation of DNA (e. g., thermal) at temperatures well below the average melting temperature (Tin). The A . T-rich segments of the molecule are denatured first. As the temperature rises, defects grow in size and increase in number. The G . C-rich segments are the last to go. Thus, if the temperature dependence of the fraction of denatured DNA is carefully measured, the resulting curve will feature sharp peaks corresponding to the partially melted structures (Fig. 8-6).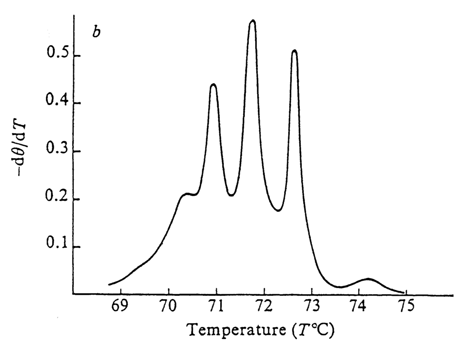
Fig. 8-6. Differential melting curve of the replicative form of (
fX174 DNA (courtesy of M. D. Frank-Kamenetskii).The denaturation process ends in the strands coming fully apart. This can be demonstrated by direct methods, such as measurement of the molecular weight (in denatured DNA it is roughly half as high as in the native one), electron microscopy, separation of strands (if they differ in buoyant density) by ultracentrifugation in the cesium salt density gradient, and so on.
In the case of DNA, the above-mentioned linear relationship between Tm, of helical double-stranded polynucleotides and the content of G . C pairs in their molecules has practical ramifications. Indeed, by experimentally determining Tm of DNA in a solution of a particular ionic strength one can find its overall nucleotide composition from a plot (e. g., that shown in Fig. 8-7).
Since Tm of helical double-stranded polynucleotides is also related linearly to the logarithm of salt concentration, the content of G - C pairs in DNA can be determined using a more general relation:
content of G . C pairs (%) = 2.44 (Tm- 81.5 - 16.6 logM),
where M is the molar concentration of a monovalent cation.
Alkaline denaturation is often used for full separation of DNA strands. To this end, the pH value of the DNA solution is brought to 12.5, and the latter is neutralized after a while.
Of particular interest is the process of DNA renaturation, whereby DNA molecules pass from the denatured into the original native state with more or less complete restoration of the secondary structure.
Renaturation of DNA calls for the same conditions as formation of helical complexes from synthetic complementary polynucleotides; that is, the temperature must be below Tm and the ionic strength of the solution must be sufficiently high. However, in this case, too, the renaturation of DNA proceeds in a much more complex manner by virtue of the heterogeneous nature of its polynucleotide chains.
If partially denatured DNA molecules (i.e., when polynucleotide strands have not yet been separated completely) undergo renaturation, if the strands are still held together after complete denaturation (i.e., by covalent crosslinking), or if we are dealing with covalently continuous cyclic DNA molecules, then the original secondary structure is restored quickly and completely.
But if renaturation takes place after complete separation of the strands, their recombination and restoration of the original structure are hampered by formation of intermediate structures through pairing of relatively short complementary segments in the same or different polynucleotide chains.
Therefore, the renaturation of DNA is conducted in such a way that the emerging spurious imperfect structures could fall apart again. A typical example is so-called renaturation by "annealing" when the DNA solution is very slowly cooled after denaturation.
It is clear that the greater the number of repeating complementary sequences in a DNA molecule and the longer they are, the lower the yield of renatured molecules will be. For instance, renaturation of animal DNAs in which such segments are numerous is slow and with a very low yield. On the contrary, in the case of bacteriophage DNAs practically free of long repeating sequences, renaturation proceeds with a high yield.
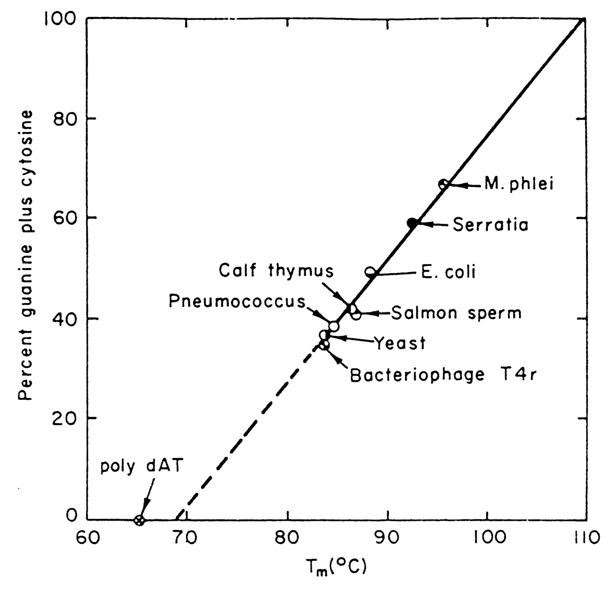
Fig. 8-7. Melting temperature of DNAs versus content of G . C pairs. The dots on the straight line correspond to different DNAs whose nucleotide composition has been determined by direct chemical methods. For a solution with ionic strength of 0.2, the straight line is given by the formula: content of G . C pairs = (Tm - 69.3) . 2.44.
Renaturation of DNAs is used to solve quite a few biological problems. A case in point is experiments aimed at isolating so-called "individual" genes. Although such experiments are merely of historical interest, they provide a vivid illustration of the possibilities of the DNA denaturation-renaturation method. Very briefly, these experiments boil down to the following. Two totally different (usually viral) DNA molecules were selected. These DNAs differed in nucleotide sequence over the entire length with the exception of the segment encoding this common protein. Both types of DNA molecules were mixed, denatured, then placed under conditions optimal for their renaturation.
Among fully renatured molecules and those remaining in the denatured state there appeared molecules formed by strands of different DNAs, which had paired over a complementary segment (the latter being much longer than the duplex helical segments in imperfect intermediate structures).
The reaction mixture was then treated with DNase specifically hydrolysing single-stranded polynucleotides. Such treatment leaves fully renatured starting DNAs in the mixture along with double-stranded DNA fragments containing "individual" genes; both differ widely in molecular weight and can easily be separated from each other (Fig. 8-8).
It has become routine in molecular biology to study the kinetics of the process of renaturation (or reassociation) of DNAs as well as DNAs and complementary RNAs (the latter process is normally referred to as molecular hybridization). Such studies are usually conducted with a view to determining the degree of similarity or, in the case of RNA-DNA hybridization, complementarity of the nucleotide sequences of two nucleic acids. While studying the DNA reassociation kinetics one can also glean interesting information about the principles on which the genetic material is organized.
In addition to the usual parameters (ionic strength and temperature), the rate of reassociation of a denatured DNA is also dependent on its concentration and size. Therefore, DNA molecules are broken down in advance to fragments of a more or less the same size with a relatively small molecular weight. After denaturation, the DNA is placed under conditions optimal for renaturation (ionic strength of about 0.2; temperature 250C below the Tm of the native DNA in the same solvent). The degree of DNA reassociation at a given point in time is determined in different ways: by the hypochromic effect, by estimating the single-stranded DNA fraction hydrolysed with nucleases specific toward such DNA, and by chromatographic methods making it possible to separate the native (renatured) and denatured DNAs. The DNA-RNA hybridization process is normally monitored by separating the hybrids from the single-stranded RNA on membrane filters.
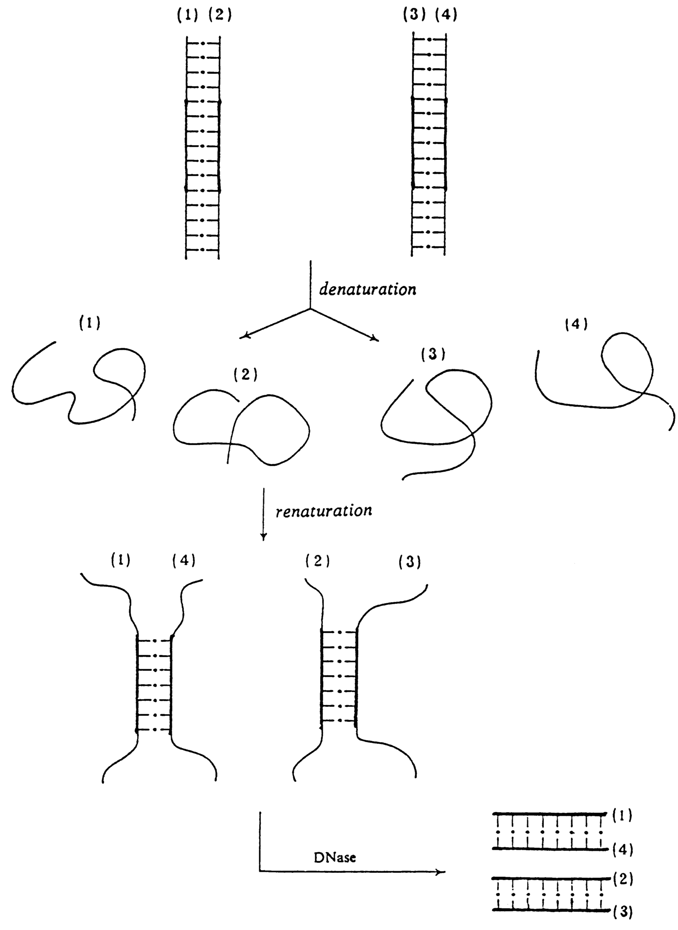
Fig. 8-8. Scheme illustrating how an individual DNA fragment is obtained by the denaturation-renaturation method.
Since the DNA reassociation process is a bimolecular reaction, the rate at which the amount of single-stranded DNA decreases is given by the equation
where C is the single-stranded DNA concentration (mole of nucleotides per liter), t is time (s), and k is the second-order rate constant (l mole-1 S-1).
Equation (1) can be easily converted into the following expression:
in which C, is the total DNA concentration (mole of nucleotides per liter); at the initial moment of the reassociation, C = C0.
As can be seen from this equation, the amount of denatured DNA not yet reassociated by instant t is a function of C0t. Therefore, the process of DNA reassociation is usually given on a "degree of renaturation versus C0t1/2 plot (Fig. 8-9). The most important quantity on the latter is C0t1/2 at which the reassociation is 50% complete (C/C0 =1/2) and which, as is shown by Eq. (2), equals the reciprocal of the reaction rate constant.
The shape of the reassociation curve depends on the number and size of the recurring nucleotide sequences in the nucleic acid molecule. In the case of viral and bacterial DNAs, the curve in its entirety fits the two logarithmic intervals C0t (Fig. 8-10) because these DNAs are virtually devoid of long repeating sequences. The value of C0t1/2 for such nucleic acids is directly dependent on their size (and, vice versa, the size of such genomes may be determined from experimental values of C0t1/2), which is precisely the reason why the reassociation curves for different DNAs in Figure 8-10 are shifted along the abscissa the way they are. This plot also shows an association curve for complementary polynucleotides that may be regarded as nucleic acids containing only one pair of nucleotides.
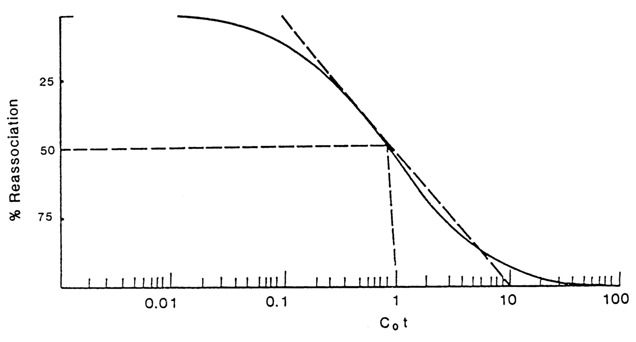
Fig. 8-9. Idealized reassociation curve for denatured DNA chains. Note that the reaction is 80 % complete within the two logarithmic intervals C0t.
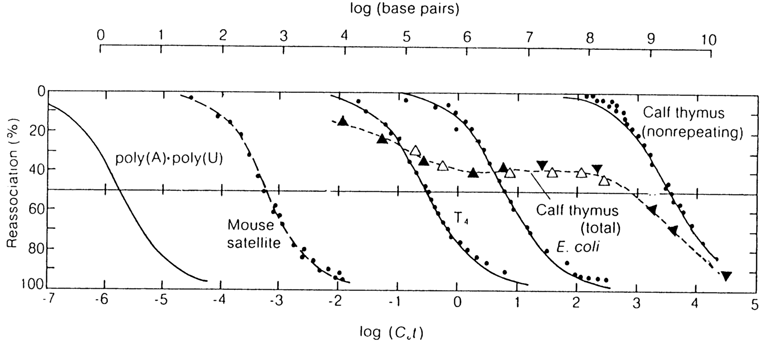
Fig. 8-10. Reassociation curves for denatured polynucleotides of different origin. Given on the upper abscissa is the number of complementary base pairs in the genome.
The reassociation curves for denatured DNAs of higher organisms indicate that their genome is composed of three main types of nucleotide sequences: those repeating frequently, those repeating at a moderate frequency, and those not repeating at all (unique sequences). Accordingly, one can discern three portions on the reassociation curves for such DNAS, each marked by its own value of C0t1/2.
Two reactions occur during DNA-RNA hybridization:
It can be easily demonstrated that when DNA is present in excess, the shape of the association curve for RNA with a denatured DNA is the same as that for the DNA-DNA association. Indeed, if the rate of the first reaction is determined from Eq. (1), the rate at which the content of single-stranded RNA decreases with concentration R is given by a similar equation:
![]() (3)
(3)
Substitution of the value of C derived from Eq. (2) into Eq. (3) gives
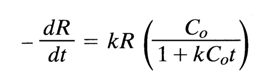
or
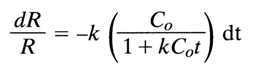
At t = 0 and R=R0, Eq. (5) integrates to the following expression:
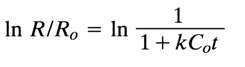
or [cf. Eq. (2)1:
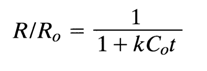
Therefore, one can determine, from the values of C0t1/2, for a given DNA-RNA hybridization process, the class of DNA sequences to which the RNA under analysis is complementary.
8.1.5 Some Aspects of DNA Behavior in Solution
The description of the hydrodynamic properties of DNA in solution constitutes a thoroughly elaborated chapter of polymer chemistry. Here, we shall only dwell on some typical features of the tertiary structure of native DNAs determining their unusual (as compared to other biopolymers) behavior in aqueous solutions.
Native DNA molecules have a rigid secondary structure (DNA exists in the B form in aqueous solutions). Consequently, DNAs in solution cannot coil into dense structures of the Gaussian type. On the other hand, native DNA samples are characterized by an inordinate molecular weight. Depending on the source and isolation technique, it may vary from millions to billions. Molecules of that size cannot retain rigidity over the entire length (i.e., be in a "rigid rod" configuration). This is why double-stranded DNA molecules form extremely bulky (or, as they are often referred to, "rigid") coils in aqueous solutions. The "rigid coil" conformation occupies an intermediate position between those of the Gaussian coil and rigid rod.
Indeed, if we consider such classical relations between the basic hydrodynamic parameters (sedimentation constant S, intrinsic viscosity [-
h], and radius Rg of gyration) and molecular weight M of the polymer as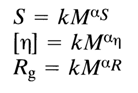
then, in the case of Gaussian coils,
aS, ah and aR are almost equal to 0.5. For molecules in a rigid rod conformation, these quantities are 0.2, 1.8 and 1.0, respectively. For native DNAs (with a molecular weight ranging from 3 to 130 . 106), aS, ah and aR were found equal to 0.4, 0.7 and 0.67.The denaturation of DNA and breakdown of the rigid ordered structure are accompanied by drastic changes in its hydrodynamic properties because the separated polynucleotide chains have a compact tertiary structure in solution, approaching that of a Gaussian coil.
The rigidity of the secondary structure and high molecular weight account for another important property of DNA. In an aqueous solution, DNA molecules "break" very easily even when the slightest hydrodynamic action is exerted. Therefore, isolation of intact native DNA molecules with a molecular weight in excess of 20 million is a challenging experimental task and calls for special precautions.